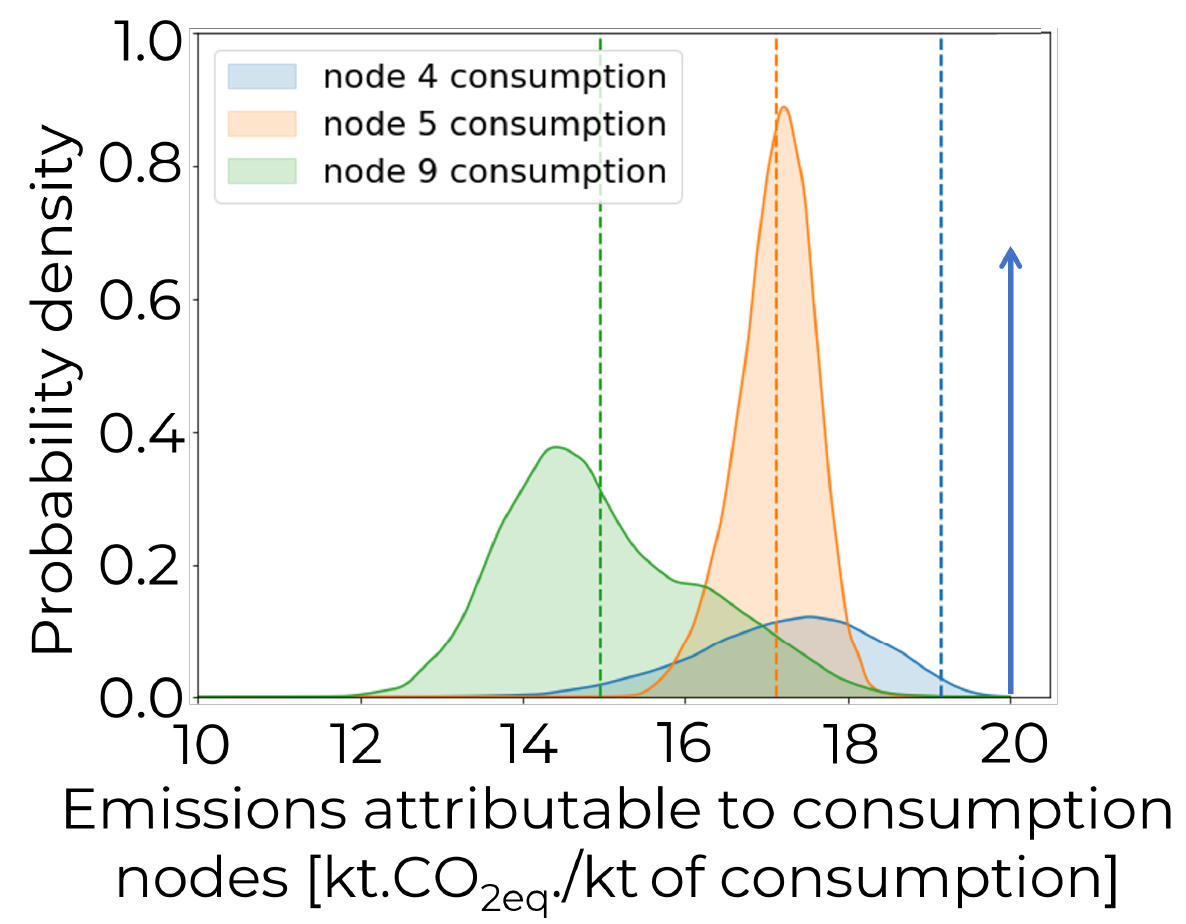
Material flow analyses (MFAs) provide insight into supply chain level opportunities for resource efficiency. MFAs can be represented as networks with nodes that represent materials, processes, sectors or locations. MFA network structural uncertainty (i.e., the existence or absence of flows between nodes) is pervasive and can undermine the reliability of the flow predictions. This article investigates MFA network structure uncertainty by proposing candidate node-and-flow structures and using Bayesian model selection to identify the most suitable structures and Bayesian model averaging to quantify the parametric mass flow uncertainty. The results of this holistic approach to MFA uncertainty are used in conjunction with the input-output (I/O) method to make risk-informed resource efficiency recommendations. These techniques are demonstrated using a case study on the U.S. steel sector where 16 candidate structures are considered. Model selection highlights 2 networks as most probable based on data collected from the United States Geological Survey and the World Steel Association. Using the I/O method, we then show that the construction sector accounts for the greatest mean share of domestic U.S. steel industry emissions while the automotive and steel products sectors have the highest mean emissions per unit of steel used in the end-use sectors. The uncertainty in the results is used to analyze which end-use sector should be the focus of demand reduction efforts under different appetites for risk. This article’s methods generate holistic and transparent MFA uncertainty that account for structural uncertainty, enabling decisions whose outcomes are more robust to the uncertainty.

Download an Excel file for the underlying data used to construct the Sankey diagrams in Figure 4 of the main article
Download Python scripts for performing Bayesian inference for both the parametric and network structure uncertainty using specified prior PDFs and collected MFA data
Download a Python script for performing MFA Bayesian model averaging and decision-making using the rectified input/output (I/O) analysis
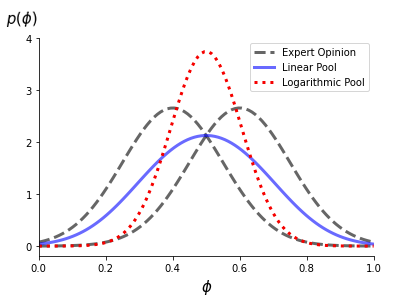
Bayesian inference allows the transparent communication of uncertainty in material flow analyses (MFAs) with the uncertainties reduced as newly collected data are included. However, the method is undermined by the difficultly of defining proper priors for the MFA parameters and quantifying the noise in the collected data. We start to address these issues by first deriving an expert elicitation framework suitable for generating MFA parameter priors. Second, we propose to learn the data noise concurrent with the parametric uncertainty. These methods are demonstrated using a case study on the 2012 U.S. steel flow. Eight experts were interviewed to elicit distributions on steel flow uncertainty from raw materials to intermediate goods. The experts’ distributions were combined and weighted depending on the expertise demonstrated in response to seeding questions. These aggregated distributions form our model priors. MFA data were then collected from the United States Geological Survey (USGS) and the World Steel Association (WSA) which are pub- lished without uncertainties. A sensible, weakly-informative prior was used to describe data noise. Bayesian inference was used to update the parametric and data noise uncertainty. The results show the reduction in MFA parametric uncertainty when incorporating the collected data. Only a modest reduction in data noise uncertainty was observed; however, greater reductions were achieved when using data from multiple years in the inference. These methods generate transparent MFA and data noise uncertainties learned from data rather than based on input uncertainty assumptions, providing a more robust basis for decision-making that affects the system.
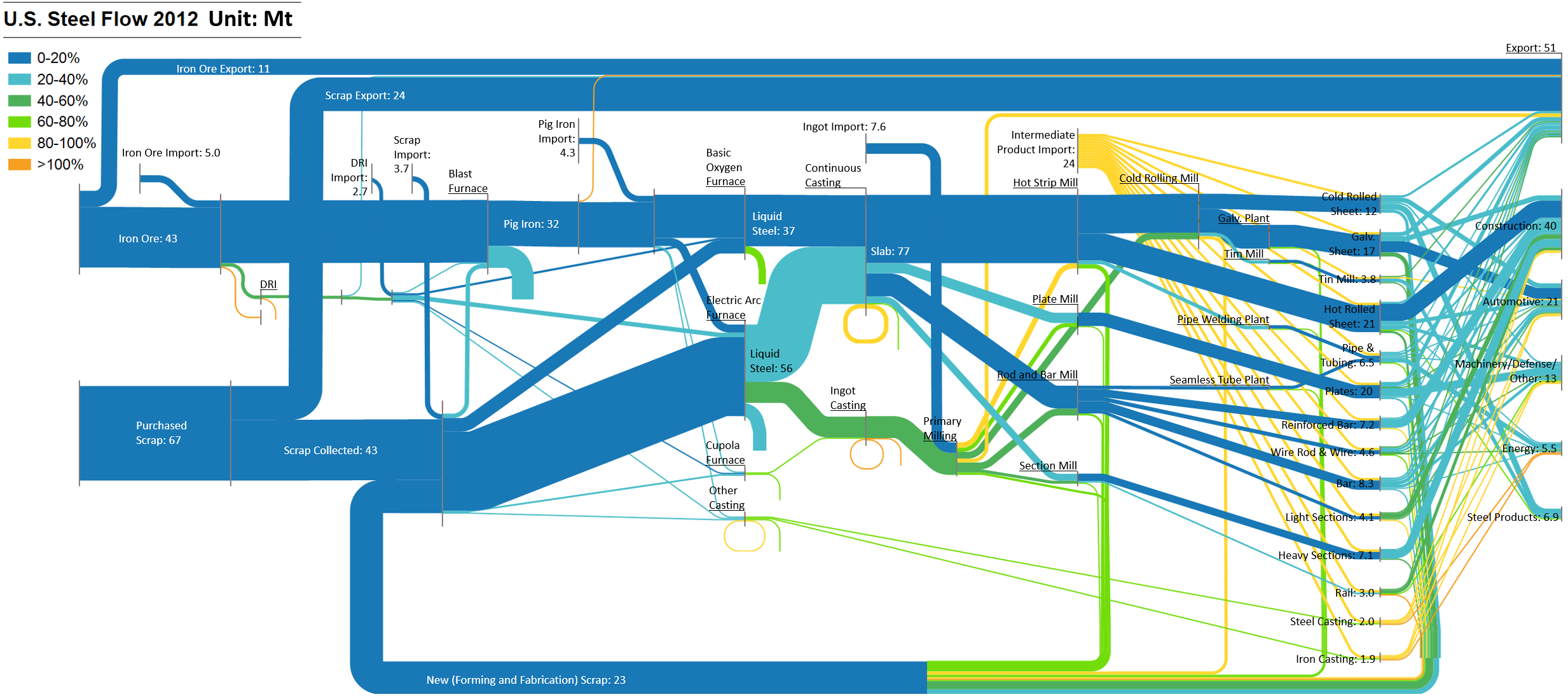
Download an Excel file for the underlying data used to construct the Sankey diagrams in Figures 5 and 6 of the main article
See here for an example Google Qualtrics survey for eliciting allocation fractions from experts
Download an Excel file for calculating expert weights based on seeding variable question responses
Download a Python script for fitting prior PDFs to the aggregated and weighted histograms from the experts
Download a Python script for performing Bayesian inference (adapted from Lupton and Allwood (2017)) using the fitted prior PDFs and USGS and WSA collected MFA data
Download a Python script for performing Bayes factor estimation to select best performing
model assumptions
Please view this website on a desktop for full content.